Training
Pretraining
- Pretraining is the act of training a model from scratch: the weights are randomly initialized, and the training starts without any prior knowledge.
- Trains on massive datasets
- Very computationally expensive
- Performed by self-supervised learning
- It is a type of training in which the objective is automatically computed from the inputs of the model
Post Training
Compute for Training Models
- Use Local CPU/GPU
- Free Hosted Compute
- Google Colab
- Kaggle Notebooks
- Rented GPU Providers
- People Rent GPUs, Data privacy depends on provider
- Vast.ai
- Runpod.io
- Jarvislabs.ai
- Managed ML Platform
- Azure ML
- AWS Sage Maker
- Google Vertex AI
Confusing…
Fine Tuning
- aka Transfer learning (or type of?)
- Training done after model has been pretrained
- In Computer Vision, this has been successfully applied already
- For image classification, knowledge gained while learning to recognize cars could be applied when trying to recognize trucks.
- We initialize weights from pretrained model and perform training on smaller dataset
- The final weights layer is modified based on the use case
- Performed by supervised learning
Steps to do Fine Tuning
- Processing the Data
- Download Training Dataset
- Tokenize
- Training
- Input Training Dataset
- Input Validation Dataset
- Setup training hyper parameters
- batch size of datasets
- number of epochs
- learning rate
- weight decay
- Define Data Collator
- Predict
- Predictions
- Labels
- Metrics
Learning Curves
Loss Curves
- Show how the model’s error (loss) changes over training steps or epochs
- Loss decreases with steps and then stabilizes (converges)
Accuracy Curves
- Show the percentage of correct predictions over training steps or epochs
- Increases with steps
Learning Patterns
- Healthy Learning
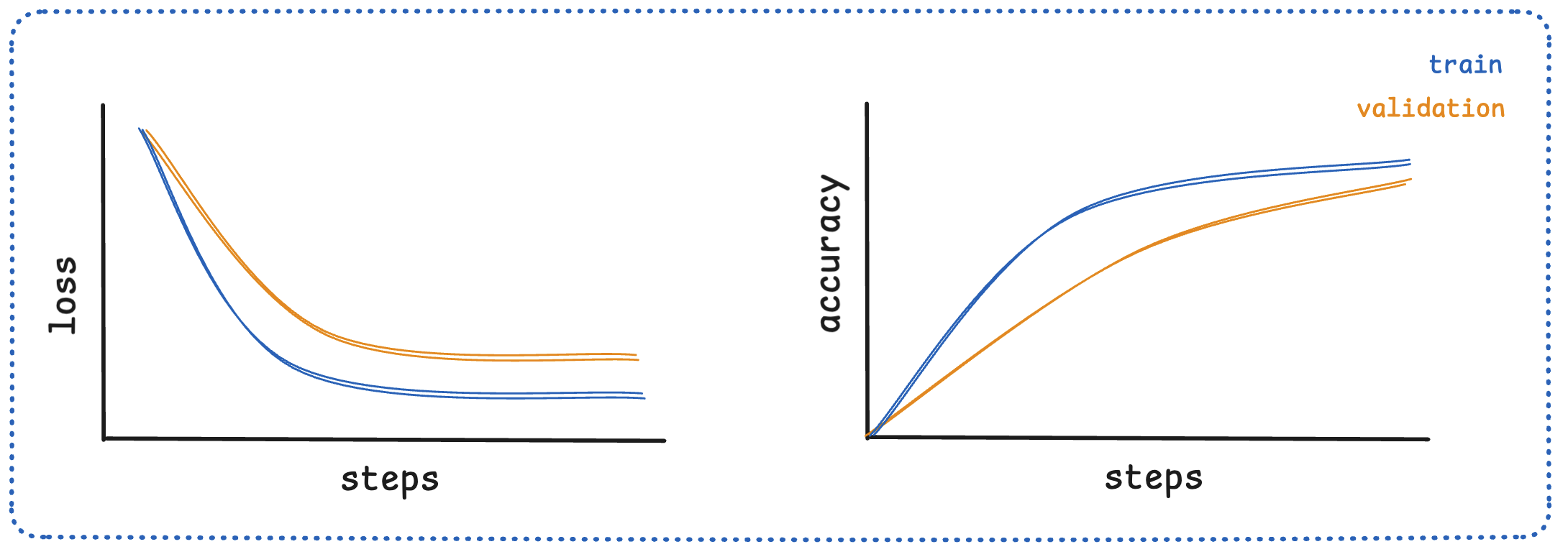
- Overfitting
- It occurs when the model learns too much from the training data and is unable to generalize to different data (represented by the validation set).
- Underfitting
- It occurs when the model is too simple to capture the underlying patterns in the data.